
Seoul National University of Science and Technology
I am a Ph.D. student at Seoul National University of Science and Technology, advised by Sangheum Hwang.
The thread running through my work is understanding what a model does not know, and when it should not be trusted. On one side, this leads me to out-of-distribution detection and uncertainty estimation, often with large-scale vision-language models such as CLIP. On the other side lies the flip problem—not detecting knowledge, but removing it—which I explore through machine unlearning in LLMs and concept erasure in text-to-image diffusion models, asking how a deployed model can reliably forget or refuse what it should no longer retain.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Seoul National University of Science and TechnologyDepartment of Data Science
Seoul National University of Science and TechnologyDepartment of Data Science
Ph.D. StudentMar. 2023 - present -
Seoul National University of Science and TechnologyB.S. in Industrial EngineeringSep. 2016 - Feb. 2022
Honors & Awards
-
Best Paper Award (KCC2026)2026
-
Ph.D. Student Research Grant (Mechanistic Interpretability of Knowledge Unlearning in Foundation Models, 50M KRW / 2years, NRF)Aug. 2025 - Aug. 2027
-
Best Paper Award (ICEIC2024)2024
-
Best Paper Award (KCC2023)2023
News
Selected Publications (view all )
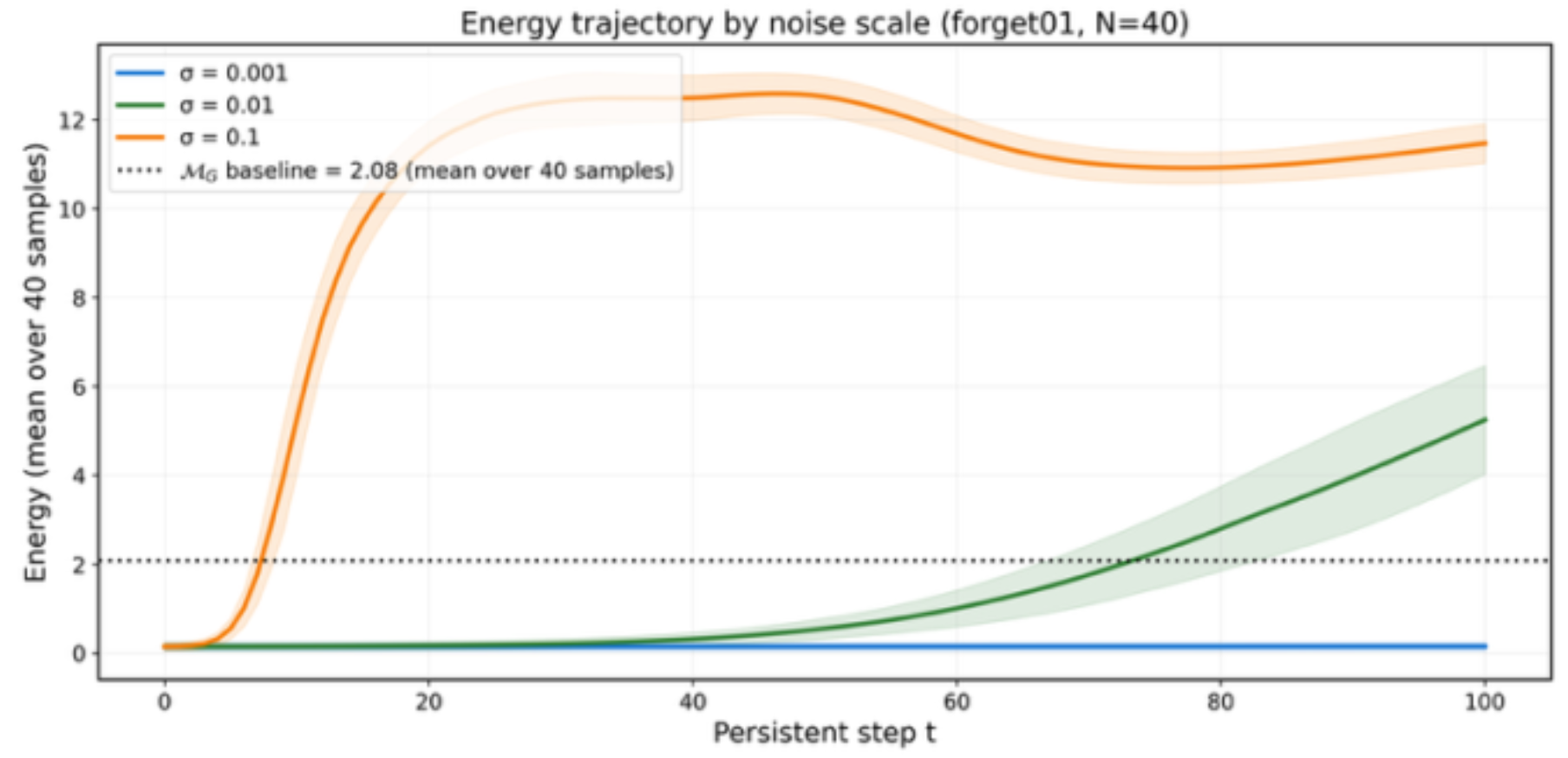
Reference-free LLM Unlearning Evaluation through Energy Trajectory Analysis
Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2026 Oral Best Paper Award
We propose a method for evaluating machine unlearning in large language models (LLMs) without a reference model—which conventional evaluation requires by retraining on the retain dataset, making it impractical for real deployment—using only the forget dataset and the original model to approximate the reference model's average energy at the dataset level. Specifically, we progressively inject direction-fixed noise into answer embeddings of a question-answering dataset to observe an energy trajectory defined by the negative log-likelihood, and find that the energy near the inflection point on this landscape closely approximates the reference model's average energy. As a result, we confirm that under the TOFU benchmark setting, the unlearning evaluation rankings from our energy-trajectory-based analysis match those obtained using the reference model directly.
Reference-free LLM Unlearning Evaluation through Energy Trajectory Analysis
Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2026 Oral Best Paper Award
We propose a method for evaluating machine unlearning in large language models (LLMs) without a reference model—which conventional evaluation requires by retraining on the retain dataset, making it impractical for real deployment—using only the forget dataset and the original model to approximate the reference model's average energy at the dataset level. Specifically, we progressively inject direction-fixed noise into answer embeddings of a question-answering dataset to observe an energy trajectory defined by the negative log-likelihood, and find that the energy near the inflection point on this landscape closely approximates the reference model's average energy. As a result, we confirm that under the TOFU benchmark setting, the unlearning evaluation rankings from our energy-trajectory-based analysis match those obtained using the reference model directly.
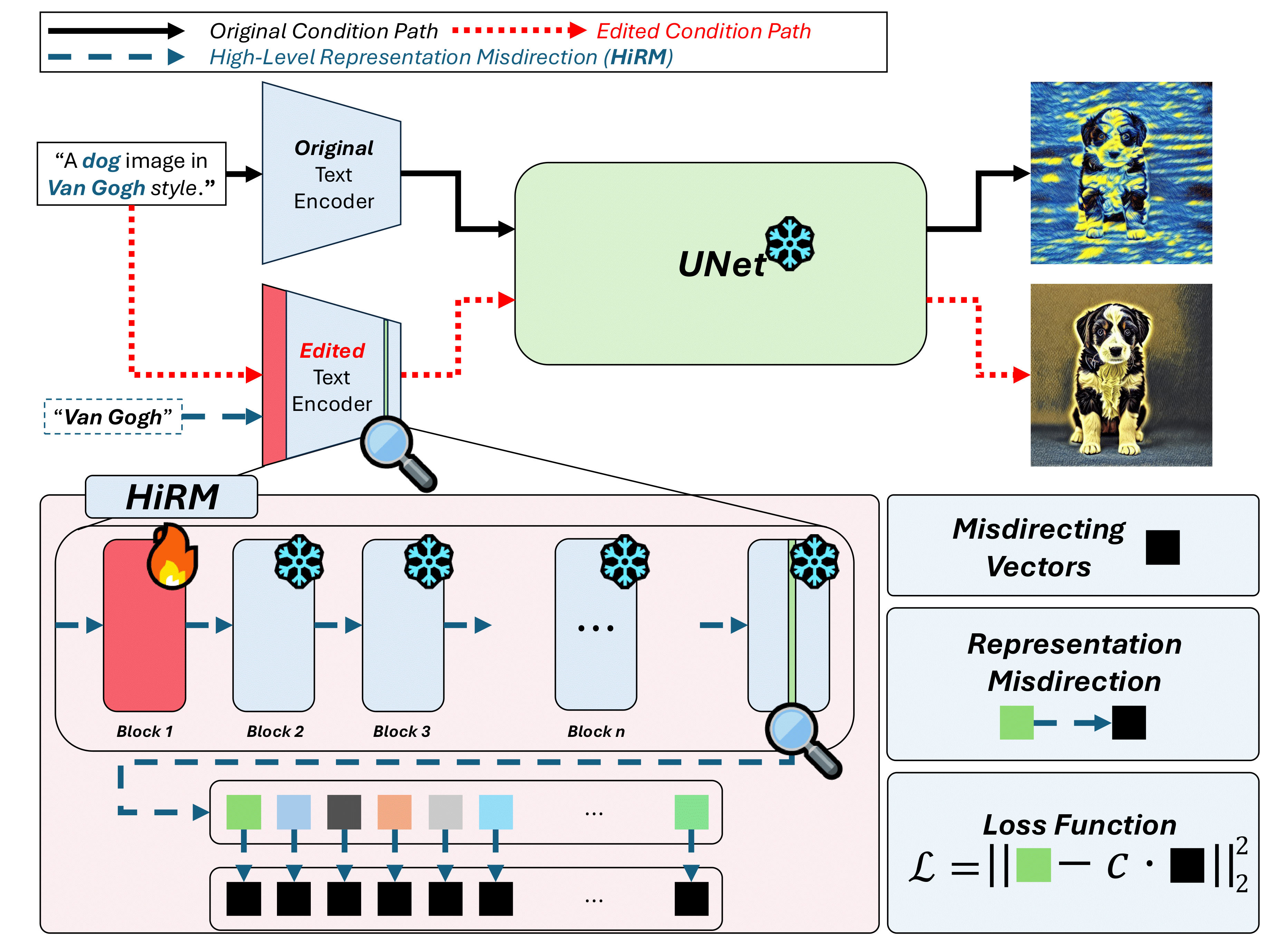
Localized Concept Erasure in Text-to-Image Diffusion Models via High-Level Representation Misdirection
Uichan Lee*, Jeonghyeon Kim*, Sangheum Hwang (* equal contribution)
International Conference on Learning Representations (ICLR) 2026
We propose High-Level Representation Misdirection (HiRM), a concept erasure method for text-to-image diffusion models that, unlike prior work targeting the denoiser, fine-tunes only the early text-encoder layers where causal studies show visual attributes are localized. HiRM misdirects the high-level semantic representations of target concepts toward designated vectors (e.g., random or super-category directions), enabling precise concept removal with minimal impact on unrelated concepts. It achieves strong results on the UnlearnCanvas and NSFW benchmarks across diverse targets, preserves generative utility at low cost, transfers to architectures like Flux without additional training, and works synergistically with denoiser-based erasure methods.
Localized Concept Erasure in Text-to-Image Diffusion Models via High-Level Representation Misdirection
Uichan Lee*, Jeonghyeon Kim*, Sangheum Hwang (* equal contribution)
International Conference on Learning Representations (ICLR) 2026
We propose High-Level Representation Misdirection (HiRM), a concept erasure method for text-to-image diffusion models that, unlike prior work targeting the denoiser, fine-tunes only the early text-encoder layers where causal studies show visual attributes are localized. HiRM misdirects the high-level semantic representations of target concepts toward designated vectors (e.g., random or super-category directions), enabling precise concept removal with minimal impact on unrelated concepts. It achieves strong results on the UnlearnCanvas and NSFW benchmarks across diverse targets, preserves generative utility at low cost, transfers to architectures like Flux without additional training, and works synergistically with denoiser-based erasure methods.
Enhanced OoD Detection through Cross-Modal Alignment of Multi-Modal Representations
Jeonghyeon Kim, Sangheum Hwang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
We show that multi-modal fine-tuning (MMFT) of vision-language models like CLIP can achieve strong out-of-distribution detection (OoDD), and identify the modality gap in in-distribution embeddings as a key limitation of naïve fine-tuning. To address this, we propose a training objective that enhances cross-modal alignment by regularizing the distances between image and text embeddings, which we theoretically show corresponds to maximum likelihood estimation of an energy-based model on a hypersphere. Combined with post-hoc methods such as NegLabel, our approach achieves state-of-the-art OoDD performance and leading ID accuracy on ImageNet-1k benchmarks.
Enhanced OoD Detection through Cross-Modal Alignment of Multi-Modal Representations
Jeonghyeon Kim, Sangheum Hwang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
We show that multi-modal fine-tuning (MMFT) of vision-language models like CLIP can achieve strong out-of-distribution detection (OoDD), and identify the modality gap in in-distribution embeddings as a key limitation of naïve fine-tuning. To address this, we propose a training objective that enhances cross-modal alignment by regularizing the distances between image and text embeddings, which we theoretically show corresponds to maximum likelihood estimation of an energy-based model on a hypersphere. Combined with post-hoc methods such as NegLabel, our approach achieves state-of-the-art OoDD performance and leading ID accuracy on ImageNet-1k benchmarks.
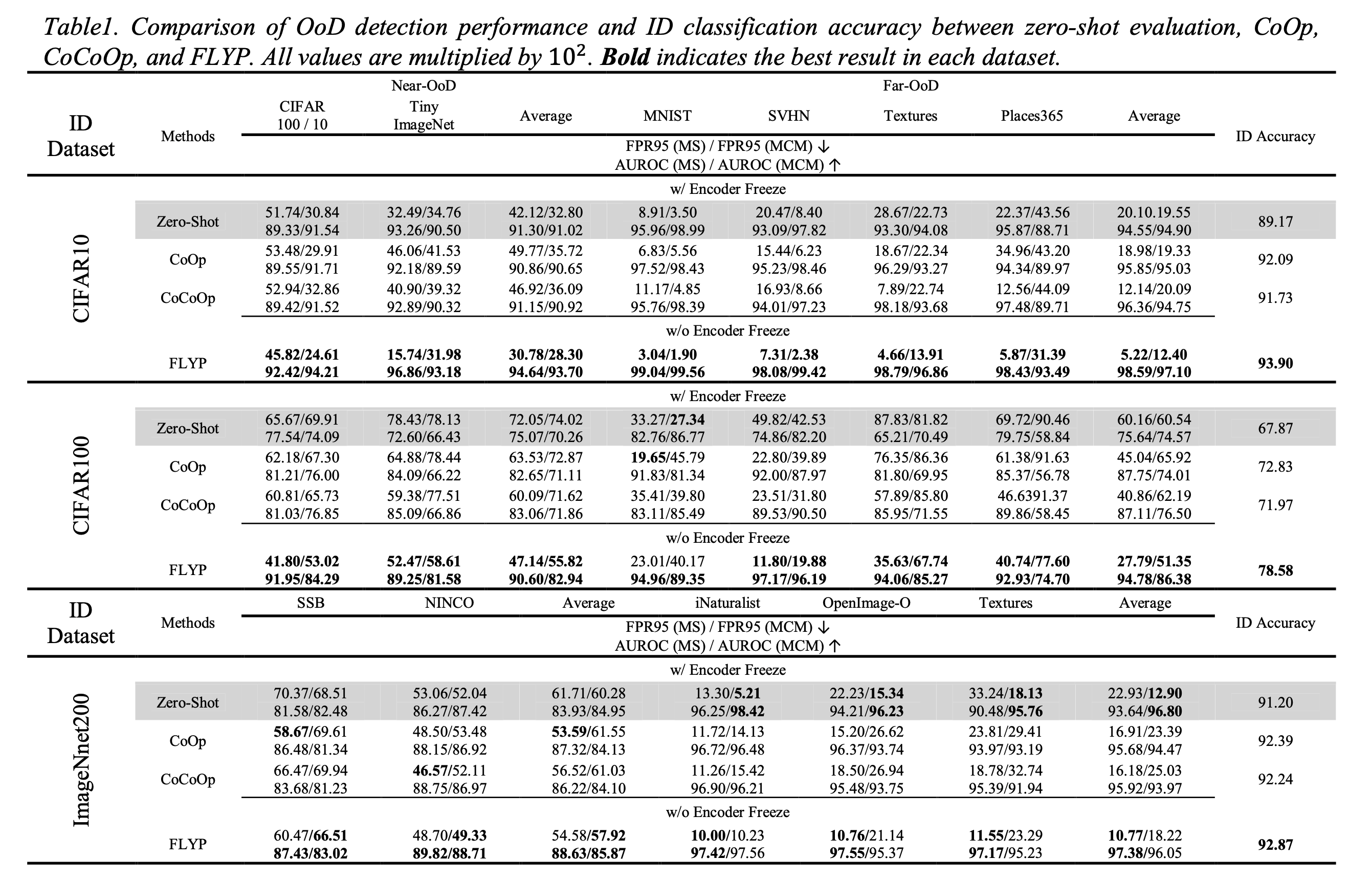
Comparison of Out-of-Distribution Detection Performance of CLIP-based Fine-Tuning Methods
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
International Conference on Electronics, Information, and Communication (ICEIC) 2024 Oral Best Paper Award
We present a comprehensive comparison of CLIP-based fine-tuning methods, evaluating not only in-distribution classification but also out-of-distribution (OOD) detection, which is often overlooked despite its importance for model reliability. Using the OpenOOD v1.5 benchmark, we analyze how different fine-tuning strategies affect both aspects of performance. Our results show that fine-tuning the entire model achieves the best performance in both classification and OOD detection under few-shot settings.
Comparison of Out-of-Distribution Detection Performance of CLIP-based Fine-Tuning Methods
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
International Conference on Electronics, Information, and Communication (ICEIC) 2024 Oral Best Paper Award
We present a comprehensive comparison of CLIP-based fine-tuning methods, evaluating not only in-distribution classification but also out-of-distribution (OOD) detection, which is often overlooked despite its importance for model reliability. Using the OpenOOD v1.5 benchmark, we analyze how different fine-tuning strategies affect both aspects of performance. Our results show that fine-tuning the entire model achieves the best performance in both classification and OOD detection under few-shot settings.
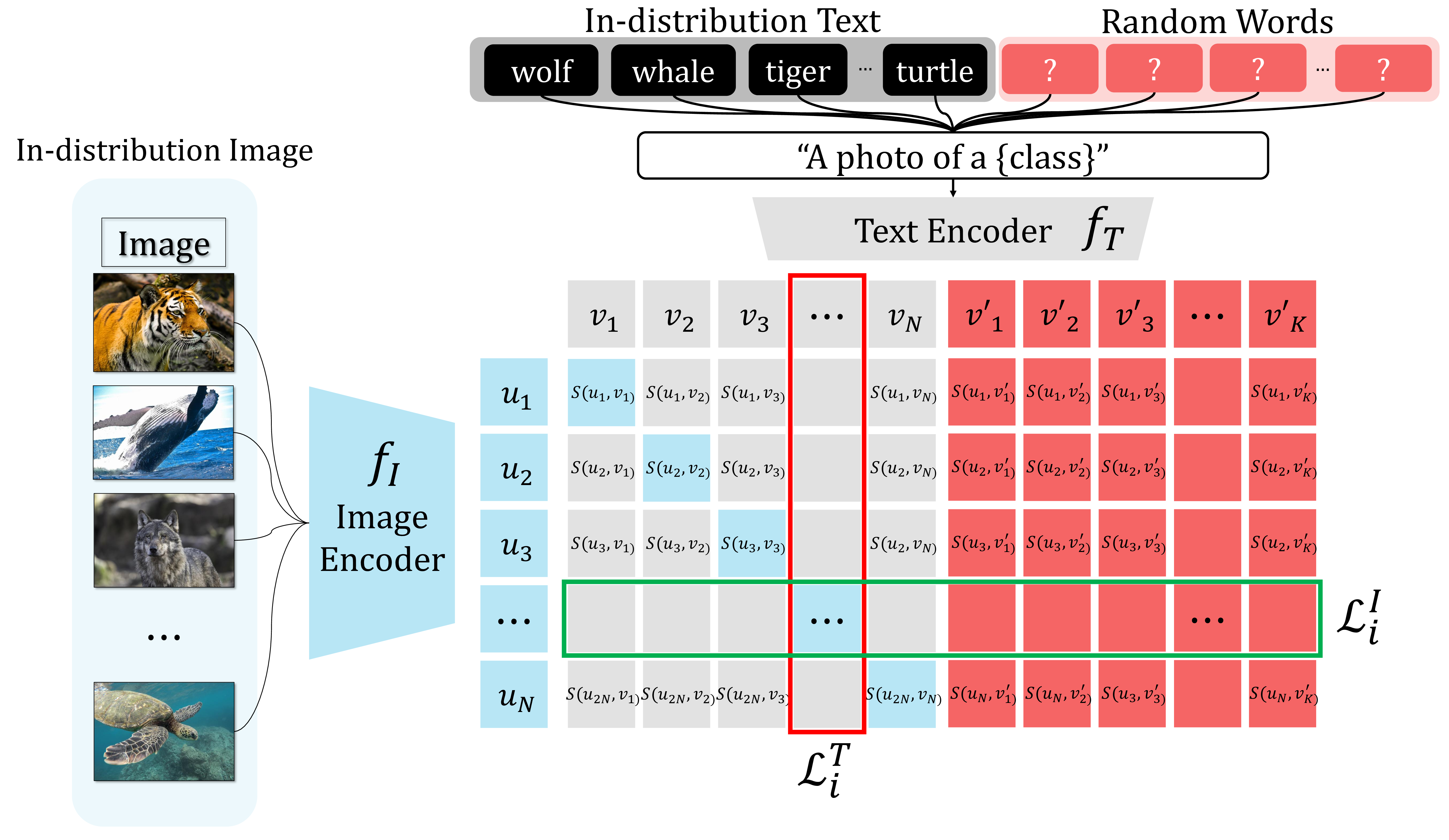
Enhancing Out-of-Distribution Detection Performance of CLIP Based on Fine-tuning with Random Texts
Jeonghyeon Kim, Jihyo Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2023 Oral Best Paper Award
We propose a method to improve the out-of-distribution (OOD) detection performance of CLIP, a vision-language model that learns from both images and text. Specifically, we apply contrastive fine-tuning using arbitrary text to a CLIP model pre-trained on large-scale internet image-text pairs. This work demonstrates the feasibility of leveraging multimodal approaches for OOD detection.
Enhancing Out-of-Distribution Detection Performance of CLIP Based on Fine-tuning with Random Texts
Jeonghyeon Kim, Jihyo Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2023 Oral Best Paper Award
We propose a method to improve the out-of-distribution (OOD) detection performance of CLIP, a vision-language model that learns from both images and text. Specifically, we apply contrastive fine-tuning using arbitrary text to a CLIP model pre-trained on large-scale internet image-text pairs. This work demonstrates the feasibility of leveraging multimodal approaches for OOD detection.