2026
Reference-free LLM Unlearning Evaluation through Energy Trajectory Analysis
Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2026 Oral Best Paper Award
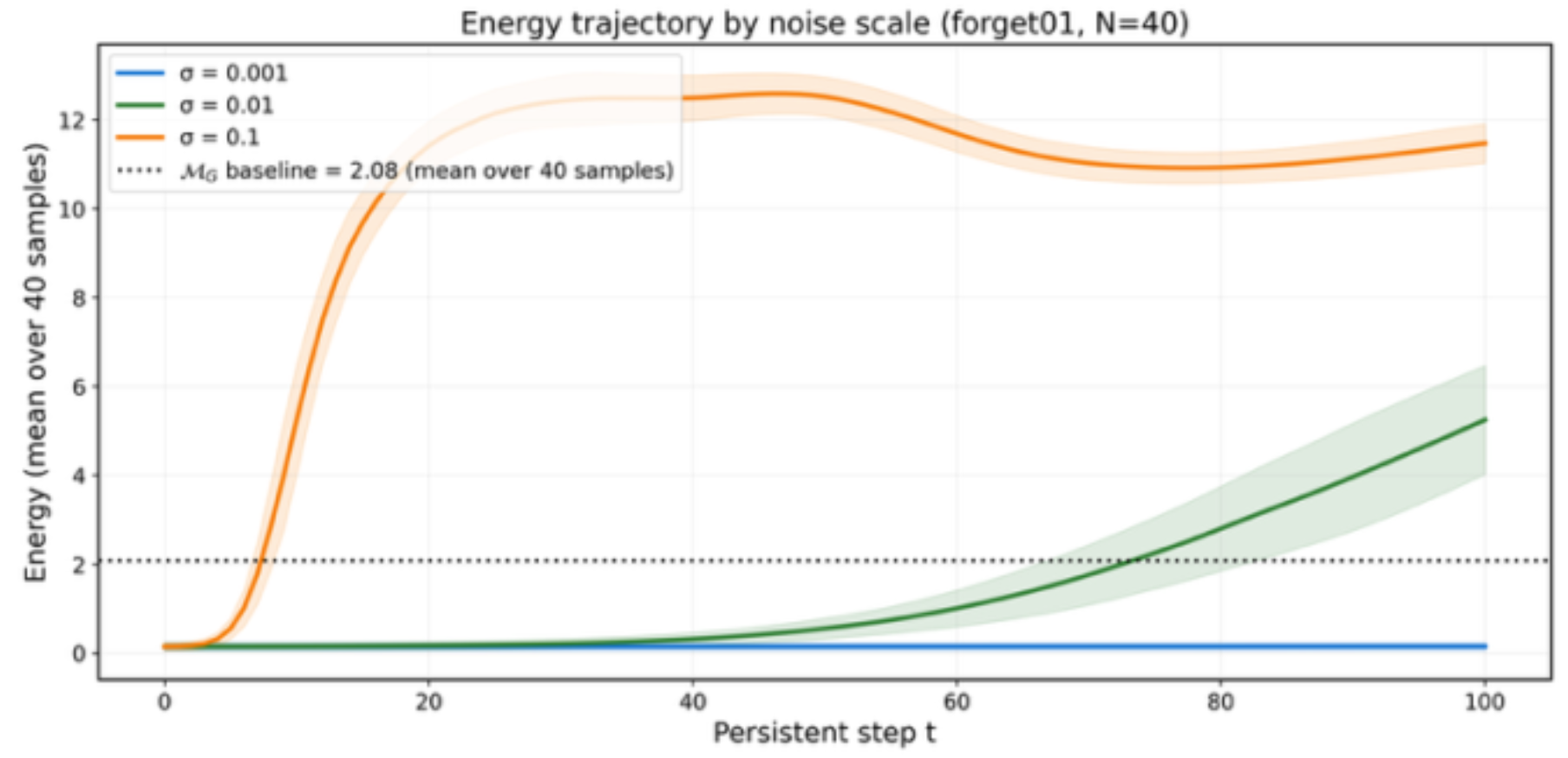
We propose a method for evaluating machine unlearning in large language models (LLMs) without a reference model—which conventional evaluation requires by retraining on the retain dataset, making it impractical for real deployment—using only the forget dataset and the original model to approximate the reference model's average energy at the dataset level. Specifically, we progressively inject direction-fixed noise into answer embeddings of a question-answering dataset to observe an energy trajectory defined by the negative log-likelihood, and find that the energy near the inflection point on this landscape closely approximates the reference model's average energy. As a result, we confirm that under the TOFU benchmark setting, the unlearning evaluation rankings from our energy-trajectory-based analysis match those obtained using the reference model directly.
Reference-free LLM Unlearning Evaluation through Energy Trajectory Analysis
Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2026 Oral Best Paper Award
We propose a method for evaluating machine unlearning in large language models (LLMs) without a reference model—which conventional evaluation requires by retraining on the retain dataset, making it impractical for real deployment—using only the forget dataset and the original model to approximate the reference model's average energy at the dataset level. Specifically, we progressively inject direction-fixed noise into answer embeddings of a question-answering dataset to observe an energy trajectory defined by the negative log-likelihood, and find that the energy near the inflection point on this landscape closely approximates the reference model's average energy. As a result, we confirm that under the TOFU benchmark setting, the unlearning evaluation rankings from our energy-trajectory-based analysis match those obtained using the reference model directly.
Localized Concept Erasure in Text-to-Image Diffusion Models via High-Level Representation Misdirection
Uichan Lee*, Jeonghyeon Kim*, Sangheum Hwang (* equal contribution)
International Conference on Learning Representations (ICLR) 2026
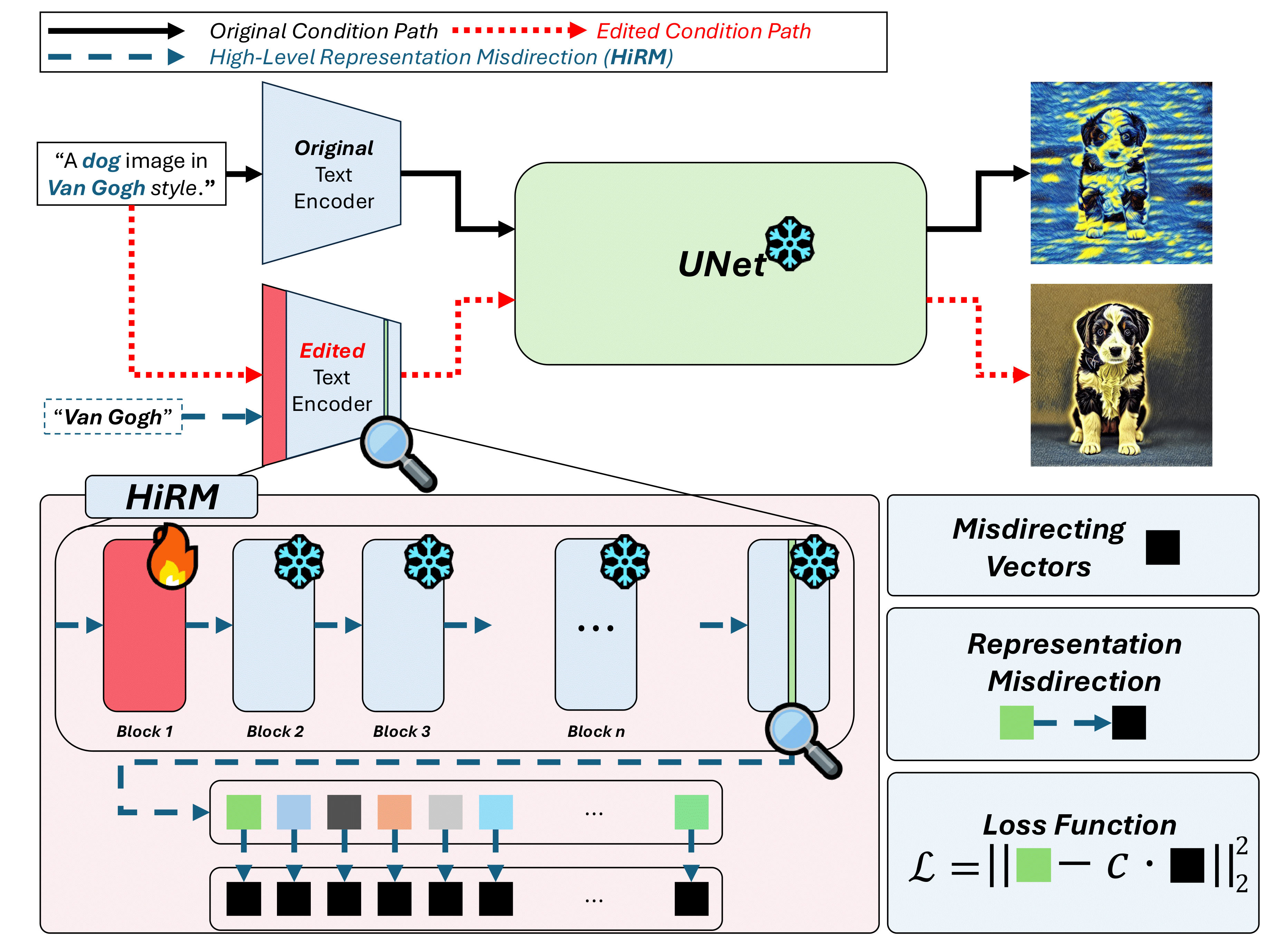
We propose High-Level Representation Misdirection (HiRM), a concept erasure method for text-to-image diffusion models that, unlike prior work targeting the denoiser, fine-tunes only the early text-encoder layers where causal studies show visual attributes are localized. HiRM misdirects the high-level semantic representations of target concepts toward designated vectors (e.g., random or super-category directions), enabling precise concept removal with minimal impact on unrelated concepts. It achieves strong results on the UnlearnCanvas and NSFW benchmarks across diverse targets, preserves generative utility at low cost, transfers to architectures like Flux without additional training, and works synergistically with denoiser-based erasure methods.
Localized Concept Erasure in Text-to-Image Diffusion Models via High-Level Representation Misdirection
Uichan Lee*, Jeonghyeon Kim*, Sangheum Hwang (* equal contribution)
International Conference on Learning Representations (ICLR) 2026
We propose High-Level Representation Misdirection (HiRM), a concept erasure method for text-to-image diffusion models that, unlike prior work targeting the denoiser, fine-tunes only the early text-encoder layers where causal studies show visual attributes are localized. HiRM misdirects the high-level semantic representations of target concepts toward designated vectors (e.g., random or super-category directions), enabling precise concept removal with minimal impact on unrelated concepts. It achieves strong results on the UnlearnCanvas and NSFW benchmarks across diverse targets, preserves generative utility at low cost, transfers to architectures like Flux without additional training, and works synergistically with denoiser-based erasure methods.
2025
Parameter-Efficient LLM Unlearning through Sparse Attention Head Updates
Deokyong Lee, Jeonghyeon Kim, Sangheum Hwang
Korean Institute of Industrial Engineers (KIIE) 2025
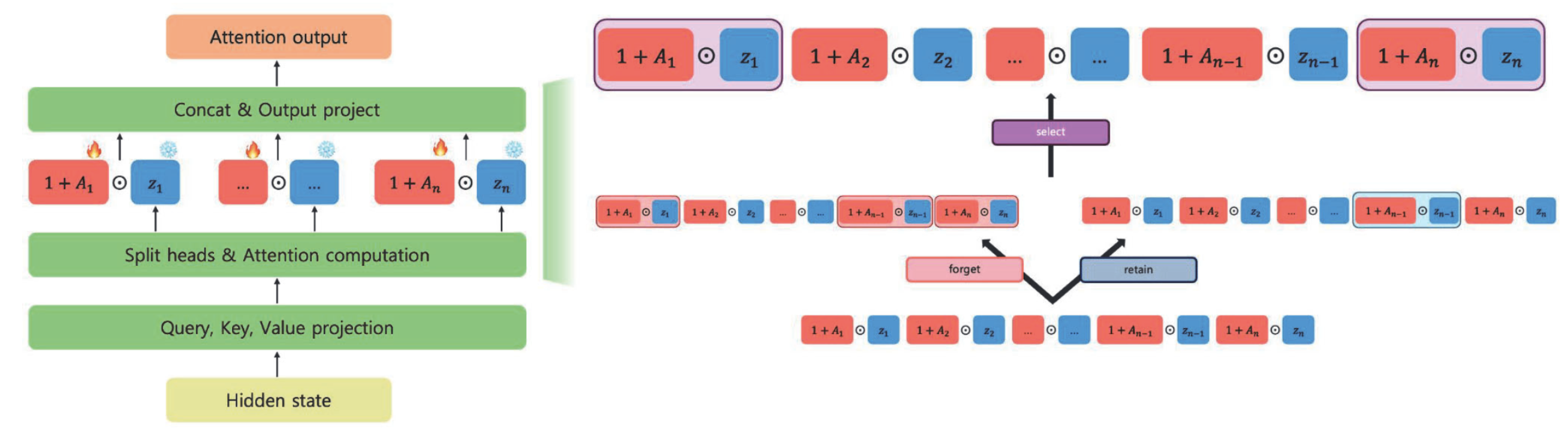
We propose a parameter-efficient unlearning method that localizes fine-tuning to a sparse subset of attention heads most associated with the forget data.
Parameter-Efficient LLM Unlearning through Sparse Attention Head Updates
Deokyong Lee, Jeonghyeon Kim, Sangheum Hwang
Korean Institute of Industrial Engineers (KIIE) 2025
We propose a parameter-efficient unlearning method that localizes fine-tuning to a sparse subset of attention heads most associated with the forget data.
Enhanced OoD Detection through Cross-Modal Alignment of Multi-Modal Representations
Jeonghyeon Kim, Sangheum Hwang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
We show that multi-modal fine-tuning (MMFT) of vision-language models like CLIP can achieve strong out-of-distribution detection (OoDD), and identify the modality gap in in-distribution embeddings as a key limitation of naïve fine-tuning. To address this, we propose a training objective that enhances cross-modal alignment by regularizing the distances between image and text embeddings, which we theoretically show corresponds to maximum likelihood estimation of an energy-based model on a hypersphere. Combined with post-hoc methods such as NegLabel, our approach achieves state-of-the-art OoDD performance and leading ID accuracy on ImageNet-1k benchmarks.
Enhanced OoD Detection through Cross-Modal Alignment of Multi-Modal Representations
Jeonghyeon Kim, Sangheum Hwang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
We show that multi-modal fine-tuning (MMFT) of vision-language models like CLIP can achieve strong out-of-distribution detection (OoDD), and identify the modality gap in in-distribution embeddings as a key limitation of naïve fine-tuning. To address this, we propose a training objective that enhances cross-modal alignment by regularizing the distances between image and text embeddings, which we theoretically show corresponds to maximum likelihood estimation of an energy-based model on a hypersphere. Combined with post-hoc methods such as NegLabel, our approach achieves state-of-the-art OoDD performance and leading ID accuracy on ImageNet-1k benchmarks.
2024
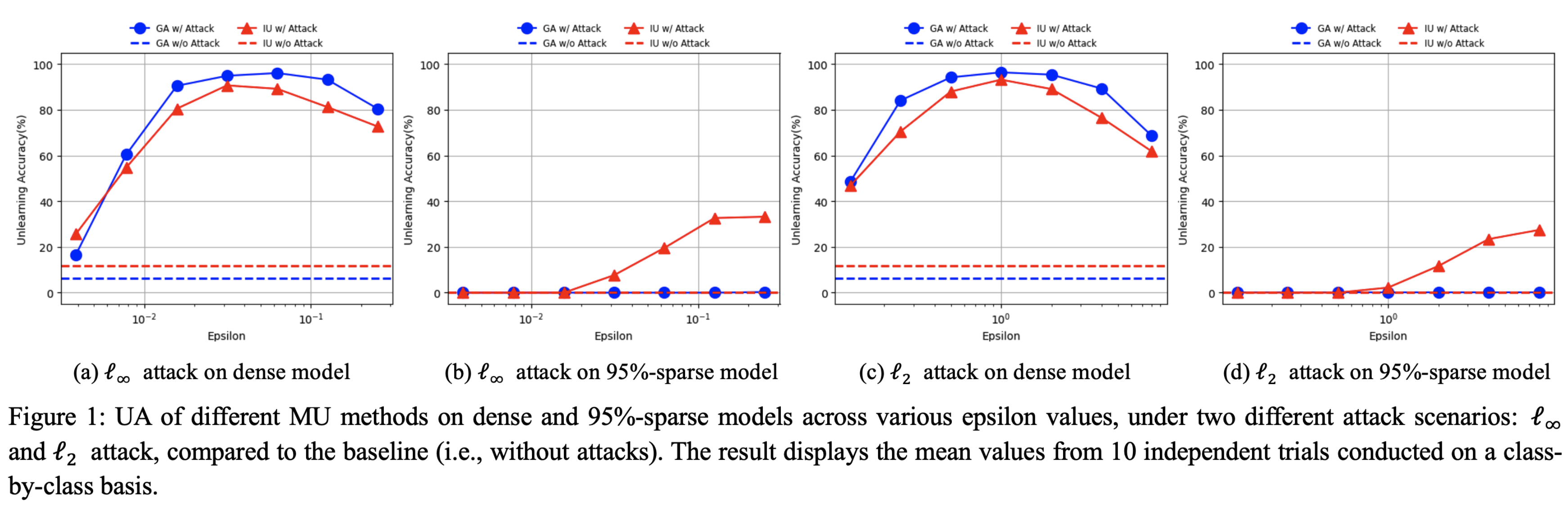
Uncovering Hidden Vulnerabilities in Machine Unlearning: Adversarial Attack
Hwiyeong Lee, Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2024
We show that adversarial attacks can force an approximately unlearned model to "recall" knowledge of the data it was supposed to forget, revealing that traces of the erased data still remain. Using this as a diagnostic tool, we examine how complete different approximate unlearning methods truly are. We empirically demonstrate that the "prune first, then unlearn" approach can serve as a complete unlearning method in terms of the unlearned model's adversarial robustness.
Uncovering Hidden Vulnerabilities in Machine Unlearning: Adversarial Attack
Hwiyeong Lee, Jeonghyeon Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2024
We show that adversarial attacks can force an approximately unlearned model to "recall" knowledge of the data it was supposed to forget, revealing that traces of the erased data still remain. Using this as a diagnostic tool, we examine how complete different approximate unlearning methods truly are. We empirically demonstrate that the "prune first, then unlearn" approach can serve as a complete unlearning method in terms of the unlearned model's adversarial robustness.
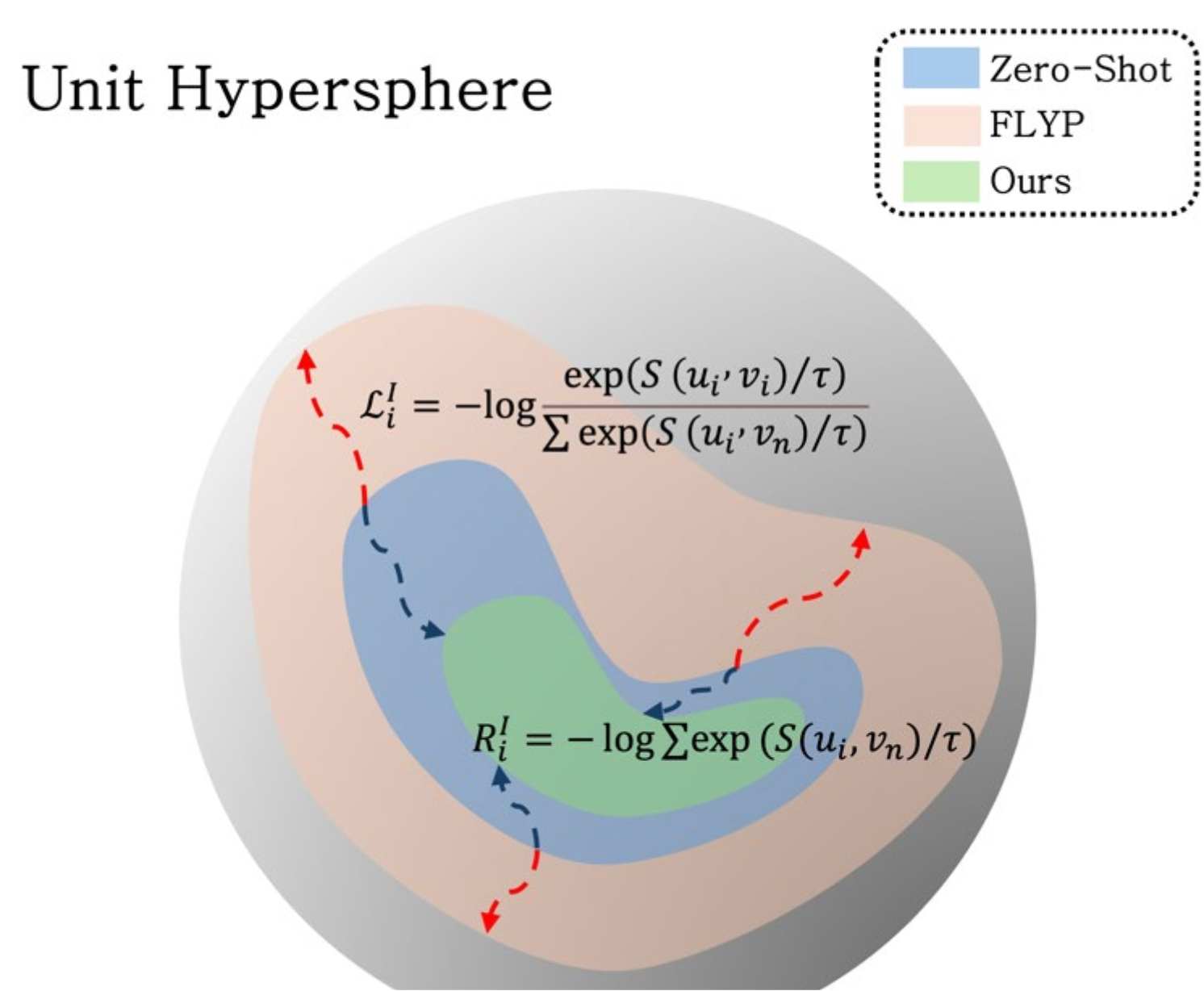
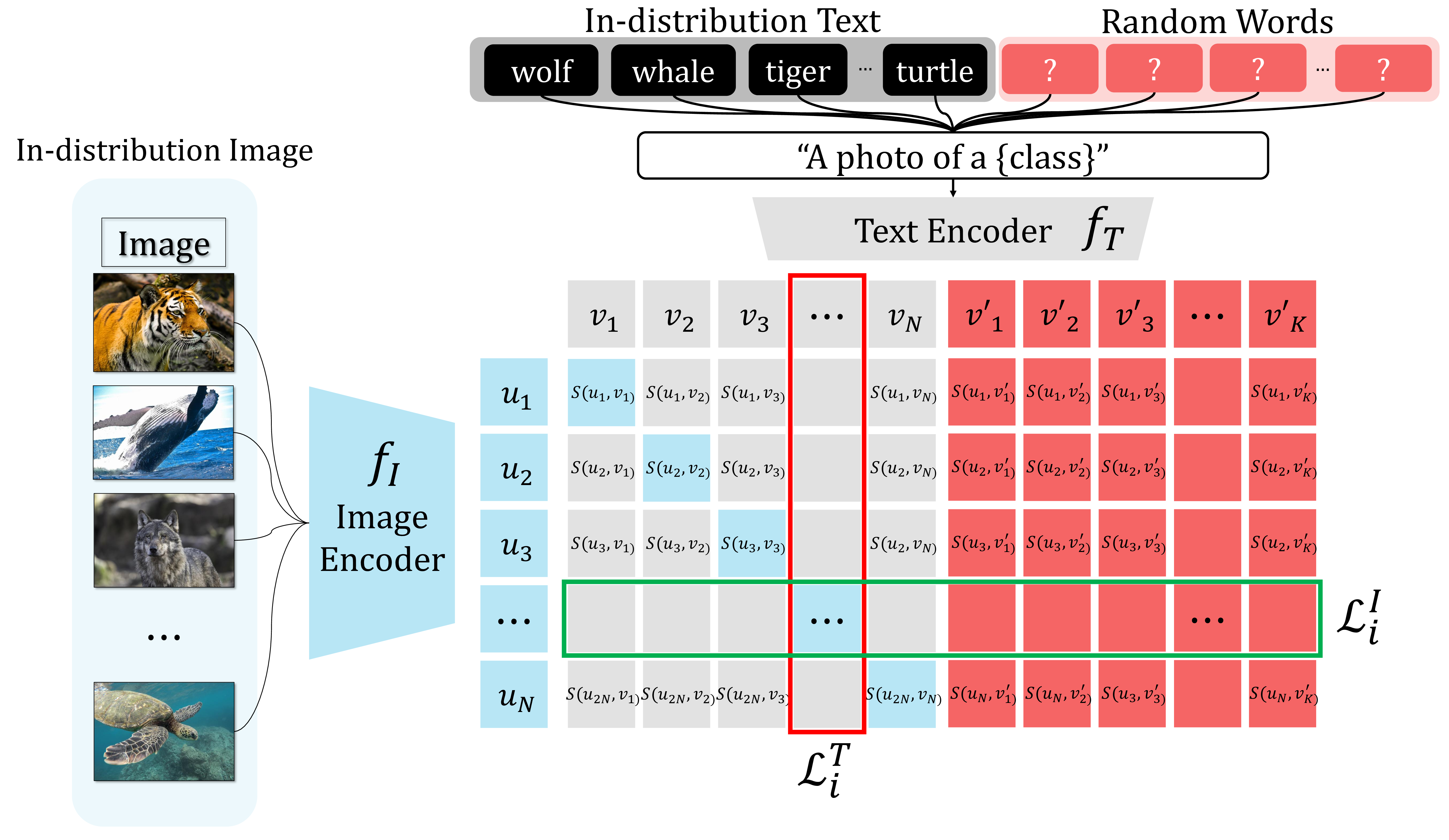
Uniformity Reduction Regularization: Multimodal Fine-tuning to Enhance Out-of-Distribution Detection Performance
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
Korea Computer Congress (KCC) 2024 Oral
We point out that FLYP, a multimodal contrastive fine-tuning method for CLIP, has limitations on out-of-distribution detection (OODD), and identify the cause as the uniformity that contrastive learning pursues. To address this, we propose Uniformity Reduction Regularization (URR), a training regularization method that mitigates this excessive uniformity. Experiments show that URR is the most effective method from a comprehensive perspective, improving not only OOD detection but also classification and OOD generalization performance.
Uniformity Reduction Regularization: Multimodal Fine-tuning to Enhance Out-of-Distribution Detection Performance
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
Korea Computer Congress (KCC) 2024 Oral
We point out that FLYP, a multimodal contrastive fine-tuning method for CLIP, has limitations on out-of-distribution detection (OODD), and identify the cause as the uniformity that contrastive learning pursues. To address this, we propose Uniformity Reduction Regularization (URR), a training regularization method that mitigates this excessive uniformity. Experiments show that URR is the most effective method from a comprehensive perspective, improving not only OOD detection but also classification and OOD generalization performance.
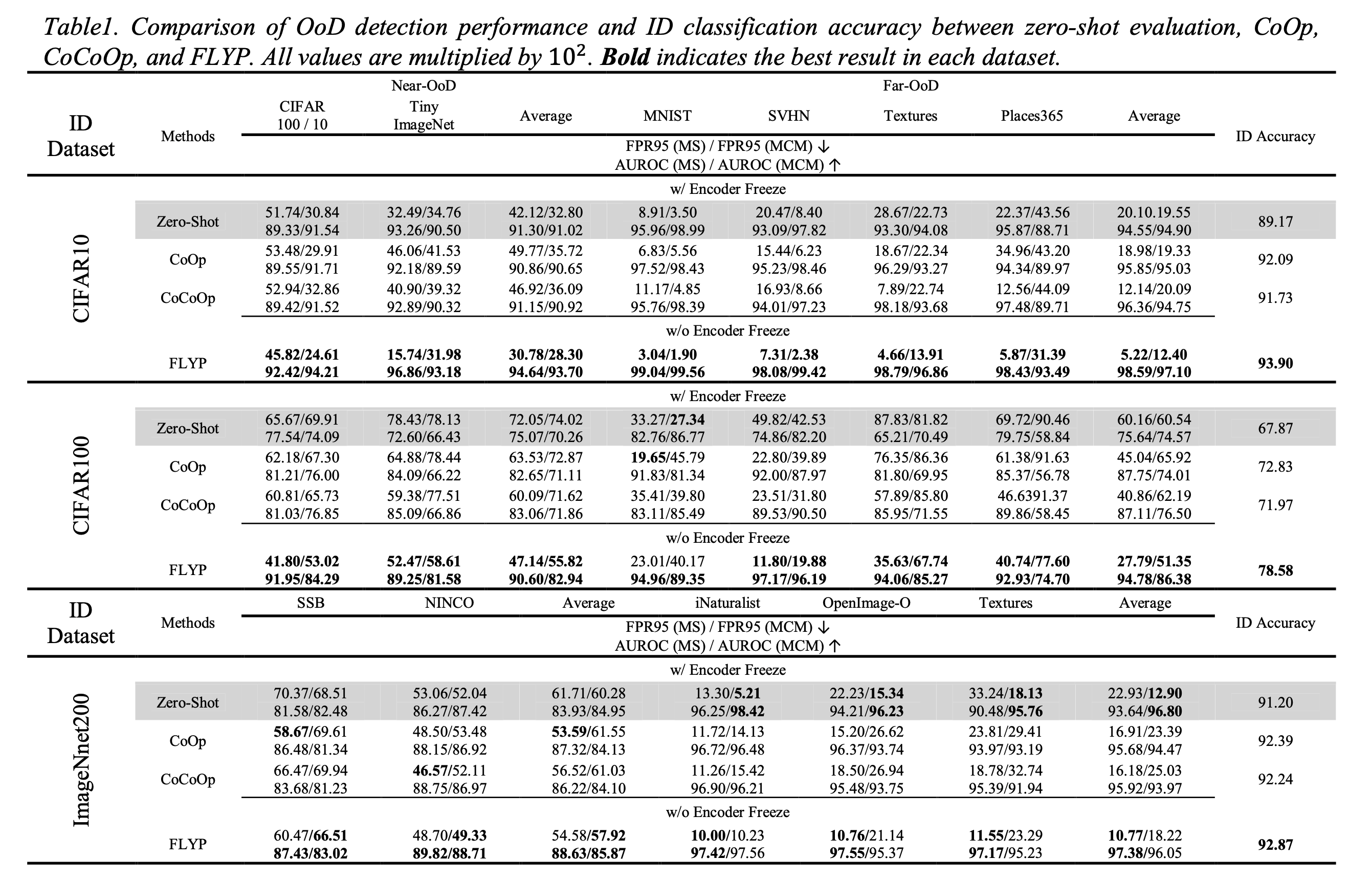
Comparison of Out-of-Distribution Detection Performance of CLIP-based Fine-Tuning Methods
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
International Conference on Electronics, Information, and Communication (ICEIC) 2024 Oral Best Paper Award
We present a comprehensive comparison of CLIP-based fine-tuning methods, evaluating not only in-distribution classification but also out-of-distribution (OOD) detection, which is often overlooked despite its importance for model reliability. Using the OpenOOD v1.5 benchmark, we analyze how different fine-tuning strategies affect both aspects of performance. Our results show that fine-tuning the entire model achieves the best performance in both classification and OOD detection under few-shot settings.
Comparison of Out-of-Distribution Detection Performance of CLIP-based Fine-Tuning Methods
Jeonghyeon Kim, Jihyo KIm, Sangheum Hwang
International Conference on Electronics, Information, and Communication (ICEIC) 2024 Oral Best Paper Award
We present a comprehensive comparison of CLIP-based fine-tuning methods, evaluating not only in-distribution classification but also out-of-distribution (OOD) detection, which is often overlooked despite its importance for model reliability. Using the OpenOOD v1.5 benchmark, we analyze how different fine-tuning strategies affect both aspects of performance. Our results show that fine-tuning the entire model achieves the best performance in both classification and OOD detection under few-shot settings.
2023
Enhancing Out-of-Distribution Detection Performance of CLIP Based on Fine-tuning with Random Texts
Jeonghyeon Kim, Jihyo Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2023 Oral Best Paper Award
We propose a method to improve the out-of-distribution (OOD) detection performance of CLIP, a vision-language model that learns from both images and text. Specifically, we apply contrastive fine-tuning using arbitrary text to a CLIP model pre-trained on large-scale internet image-text pairs. This work demonstrates the feasibility of leveraging multimodal approaches for OOD detection.
Enhancing Out-of-Distribution Detection Performance of CLIP Based on Fine-tuning with Random Texts
Jeonghyeon Kim, Jihyo Kim, Sangheum Hwang
Korea Computer Congress (KCC) 2023 Oral Best Paper Award
We propose a method to improve the out-of-distribution (OOD) detection performance of CLIP, a vision-language model that learns from both images and text. Specifically, we apply contrastive fine-tuning using arbitrary text to a CLIP model pre-trained on large-scale internet image-text pairs. This work demonstrates the feasibility of leveraging multimodal approaches for OOD detection.
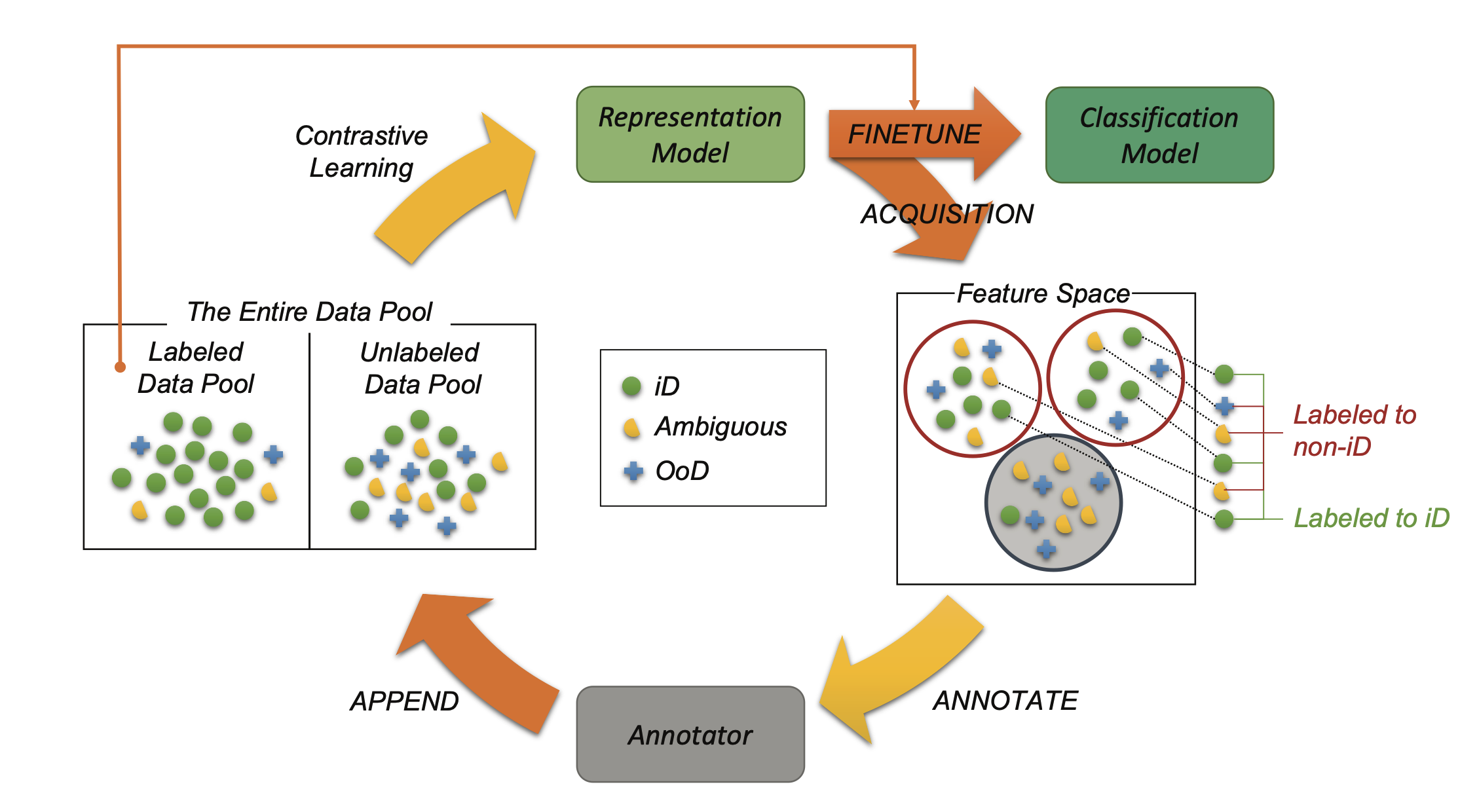
Deep Active Learning with Contrastive Learning Under Realistic Data Pool Assumptions
Jihyo Kim, Jeonghyeon Kim, Sangheum Hwang
AAAI Workshop on Practical Deep Learning in the Wild 2023
We introduce more realistic active learning benchmarks whose unlabeled data pools contain not only in-distribution samples but also ambiguous and task-irrelevant out-of-distribution ones. To handle this setting, we propose an active learning method that prioritizes informative in-distribution samples by selecting from clusters in a contrastively learned feature space, using both labeled and unlabeled data. Experiments show that our method reaches the same accuracy as existing methods while requiring a lower annotation budget.
Deep Active Learning with Contrastive Learning Under Realistic Data Pool Assumptions
Jihyo Kim, Jeonghyeon Kim, Sangheum Hwang
AAAI Workshop on Practical Deep Learning in the Wild 2023
We introduce more realistic active learning benchmarks whose unlabeled data pools contain not only in-distribution samples but also ambiguous and task-irrelevant out-of-distribution ones. To handle this setting, we propose an active learning method that prioritizes informative in-distribution samples by selecting from clusters in a contrastively learned feature space, using both labeled and unlabeled data. Experiments show that our method reaches the same accuracy as existing methods while requiring a lower annotation budget.